Data lineage is seldom synonymous to understanding data transformation…
With a rich history of lineage discussions over my career, I have come to realize that far too many people are convinced data lineage is some zen-like key to understanding their data. I find this to be a fundamental misconception. Sadly, it is also trending as the norm. Quality, governance, observability — you name it — for any number of data management functions, too many practitioners are convinced that lineage is the answer.
I believe data lineage to be one of the most over-indexed buzz terms in the data industry, so let’s explore if lineage actually lives up to the hype.
Transformation IS Business Context
Data lifecycles are often complex for many reasons. Some of which are good; some of which are not good. At no time has this been more prevalent than in today’s modern stack era, where hundreds of apps and micro-services create thousands of neural dsp-style information pathways within the modern enterprise. As a bi-product of this complexity, it can be very difficult to understand the atypical journey data takes on its way to becoming meaningful information. My point of view is that lineage is really just another of these metadata signals and, as with most metadata, lineage traces almost always require additional context to understand just what has happened to the data on its path. Unfortunately, many lineage tools lack the supporting metadata as it relates to any actual transformations. That’s why business users who are trying to visualize a data flow often struggle to figure it out on their own — they simply lack the context.
Lineage Fundamental: Without context, a lineage flow only gives the analyst a starting point for further analysis.
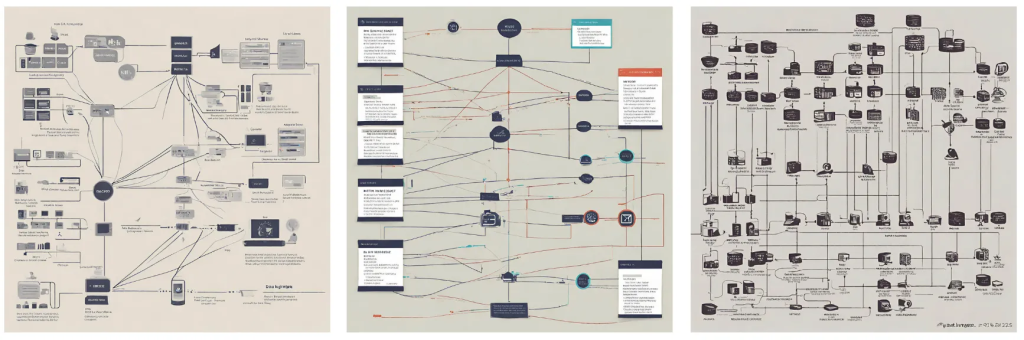
Let’s start by looking at the ways people typically understand lineage. For practical reasons, lineage is typically visualized as a data flow exercise. There are several ways to capture how data flows, but for most humans this is best understood through visualization, an example of which is depicted in Figure 1.
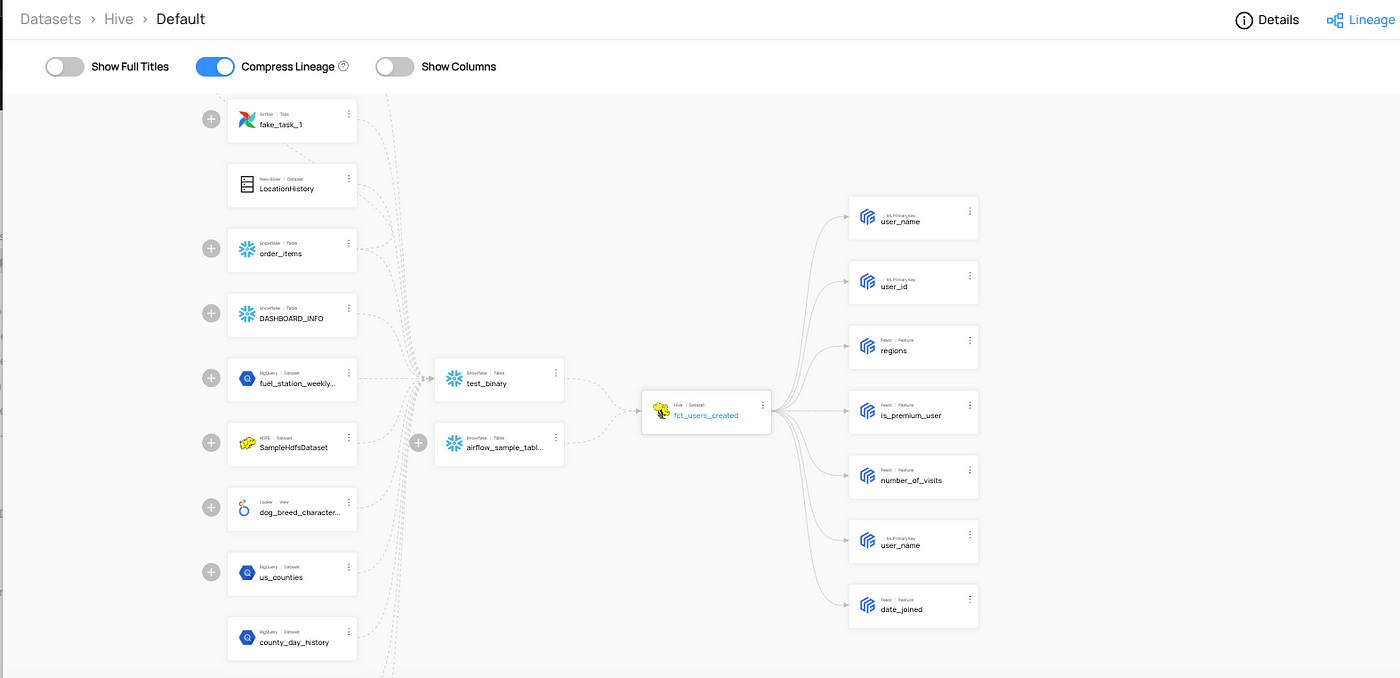
Technically oriented people assume that a lineage map will give them meaningful insight into the data lifecycle. While this may be true to some degree, understanding the pathway may actually have little to no impact on the transformation or subsequent outcomes, as outlined above. They are at the mercy of code inspections and interpretations of how the data may or may not have been impacted — i.e. transformed.
Finding the T in ETL
Some of the best examples of how transformation gets buried can be found when using ETL technologies. ETL, which stands for extract, transform and load, is at the heart of most large scale legacy data environments. I’d estimate that ~85% of all lineage traces discovered via ETL jobs may be of little to no value to business users. This is largely due to the fact that actual transformations (ex: if A +B = C, then D) usually manifest in proprietary code such as embedded SQL, JAVA or Python. Surfacing transformation code should be a key outcome of any lineage tool investment; anything short of this should be a red flag for data and business leaders. If the T in ETL isn’t obvious, then it likely will not be understood.
Key Takeaway: If your lineage tools cannot interpret the business logic by parsing various programming languages, the business logic will be obscured from your business users.
Any transformation happening in this layer is almost surely the domain of the system programmer. Care to guess how often the programmers don’t align with the business users? Not to disparage the often-amazing work done by pipeline engineers, but if we’re keeping it real, far too often this work is several times removed from the real business process. Well, at least the business understanding.
There is an upside here, as there are many reasons to appreciate the importance of the path data takes in its journey. Often times lineage is very useful in rationalizing over-complex data transports — lineage traces can easily help to identify the systems of origin or duplicated data paths that may or may not be in sync. Many will claim, however, that it’s in lineage where transformation likely occurs. As mentioned, that may be, but more often than not this is incorrect. Lineage is typically nothing more than the tracing of the data’s path from inception to consumption.
Understanding Data Flow
Using ingestion tools to process data can easily break downstream business process for the long term. This is true when the ingestion routine focuses on modifying source data to meet tactical or short term reporting needs. Once done, the resulting data set can be either incorrect, or simply have too narrow a filter applied. This has been a known issue for many years. Unfortunately, changing out transformation technologies and their supporting architectures has often been a too difficult for IT organizations. Factors that make this difficult can vary, but usually are associated to things like sunk costs for platform CAPEX , or the risk introduced by the sheer integration volume — most of which becomes increasingly more fragile over time.
In 2015, I looked for ways to reduce our ETL complexity while leading the enterprise architecture team at the Harley-Davidson Motor Company. My business leaders often relied on my team to to answer any number of questions for which we may or may not have been prepared for. Given the complexity of that global business model, we found that modeling techniques such as data flow models (see figure 2) went along way to understanding not only the path that data takes, but also they highlighted where transformation was occurring.
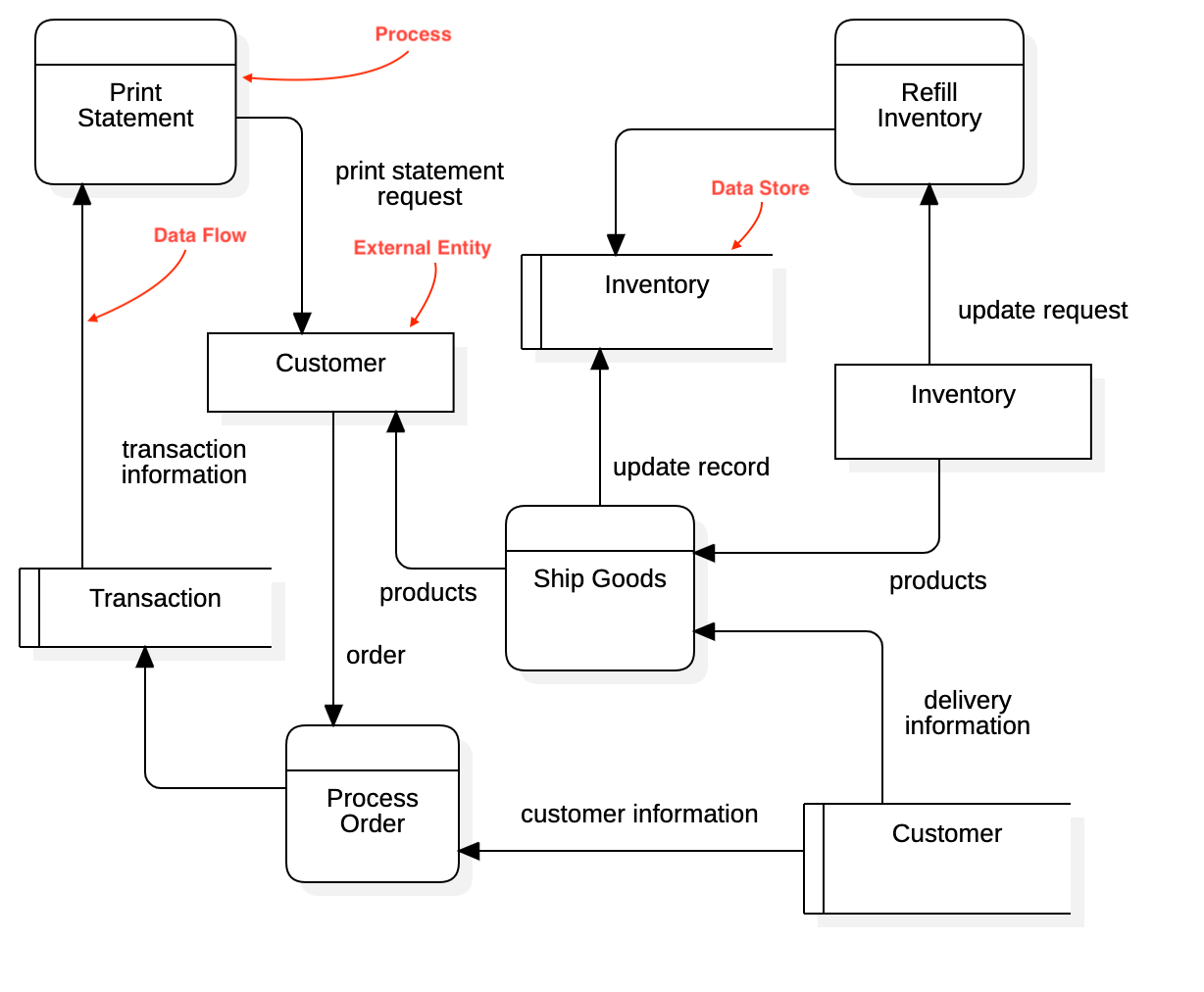
While helpful, these manual assessments and process models are simply unable to scale in these modern times. First, they’re too resource intensive and take far too long to develop. Secondly, once created, these models become quickly out of date and brittle.
Horizon Check: Data Observability
So, what is the answer? There are few all-in-one solutions unless you push all in on an architecture comprised of “best-of-breed” specific tools. This approach often won’t cross the gap between technology and business users, but it will drive improvements.
As for data observability tooling, I think the jury is still out on the efficacy of observability relative to data transformation. For many of the current offerings, the focus remains on detection and resolution of quality-centric issues. Still, several of the emerging DO tools go a long way to help with change state, and may add significant improvements to understanding transformation in the data lifecycle. To that point, I often advise that anyone with large data transports in place add some form of observability tooling. I still think that this fundamentally remains a business problem that is better served with sound Enterprise Stewardship practices over the data domains themselves. Metadata documentation, and change management process with supporting policy are still critical to understanding and capturing data transformation, and as a result platforms still seem to have gaps at least as it relates to business users.
The first step, however is setting expectations that lineage isn’t all that it’s cracked up to be.
Images courtesy of Creative Commons license.