Data quality conversations can be tiresome. Due in large part to people not understanding why their data is poor. This results in speculation as to how it got that way. The fact that bad data often goes un-noticed until it’s really needed doesn’t help matters.
Admittedly the title of this piece may stray into click-bait territory, but even if you’re a little savvy when it comes to corporate data you’re probably not surprised to learn you have data quality issues somewhere in the stream.
So given that data quality will always be a part of the broader data landscape, what should you do about it?
Know Why It Matters
First, it’s really important to make sure everyone in the organization understands why quality data is important. I don’t mean “of course [it’s important]” kind of head nodding, but more like a make-it-so kind of understanding. Like most things, this requires leadership, some competent data stewards and the right technology investments.
Business leaders and executives have little patience for poor data, and even less patience for the risk and rework that it introduces; especially inaccurate reporting. Poor quality data is just plain expensive to own. Not to mention the risk it introduces into business process, deals, reporting, invoicing — you name it. Bad data can often be directly tied to productivity and efficiency issues as well. I personally recall a conversation with my then CFO who wanted to know how come we couldn’t certify the number of units sold per month. Turns out that was kind of a big deal. It was a very uncomfortable discussion.
Examples such as this abound, which may be driving the emergence of roles like that of Chief Data Officer, whom in many cases has one job: Drive and govern data quality improvements. But this should be everybody’s job. Anyone who creates, modifies or consumes data has a stewardship responsibility.
There’s also a lot of upside, as there are many benefits to improving quality. Not only can data can be used to unlock additional value for your business, but it opens up opportunities to drive new outcomes, reduce risk, improve customer relations and even establish new markets.
Lastly, data quality left unchecked puts you and your company’s reputation at stake. Among other things, bad data makes everyone wonder if they’ve got the right people, business partner or supplier. If you’re too daft or unable to manage your own DQ issues, why should anyone else trust you with their data?
Garbage In…
First of all – Duh. Let’s just call out the obvious: A portion of all data should be considered suspect and likely non-conforming. If your story is “my data sucks and I don’t know why”, know that you’re not alone. As I stated earlier, how you handle it may set you and your company apart.
Understanding your data lifecycles is a likely good first step. Long before data makes it’s way to decision making or analytic view points, it must first be collected. Peeling back the onion to understand the origins of data inputs, quality issues are often linked directly to source capture. This can be impacted by several factors including lack of testing when developing apps, poor data entry, and poorly constructed APIs. Source capture requires discipline. In years past the software industry enjoyed a higher level of interface design, testing and data validation. Sadly, these days the emphasis is shifting from truly understanding ‘business’ data to more of a focus on rapid delivery, followed by limited, or sometimes down-right poor end-user training. The rise of UX in the mid-1990s ensured that many apps remain workflow-centric to this day, rather than data-centric. The result is that data-aware development techniques are diminishing amongst modern software designers and development teams. It’s becoming a lost art as data capture validation at the point of inception has been relegated to skills of the past. But back to the point — the lack of validation rules where the data is getting entered continues to be the #1 source for bad data.
To Transform or Not
The second most likely failure point will be in the transport layer, or pipeline. The pipeline consists of the tools that move and modify data from source systems into downstream systems such as analytical and reporting platforms. These are the data lakes and warehouses in most enterprises, but can take other forms as well.
The definitive platforms for data transportation are ETL tools. ETL is an acronym for the extraction, transformation and loading of data. Sadly, far too much business logic resides in these platforms, out of the critical oversight of the the business stakeholders. The implication being that programmers or automation systems apply algorithms and functions to merge or coalesce the data for consumption. It’s here that quality problems are often introduced being disconnected from a deep understanding of the business functions. They’re just not visible or accessible to mere mortals.
Note — Luckily ETL is being gradually replaced with in-database ELT, which puts the transformation function at the end of the chain and more readily visible in SQL code that many analysts can understand and interpret.
Where to Focus
Some fundamental best practices, when coupled with metrics-based leadership and commitment can turn the tide on chronically bad data. One such practice would be the early engagement of Enterprise Stewards in the procurement process. A deep inspection of data outputs from applications under consideration for purchase should be a fundamental part of any RFI or RFP. Another foundational practice is to ask development and data engineering teams ‘show their work’, allowing business stakeholders to inspect data transformation work. Does A + B actually equal C?
My work provides me the opportunity to speak daily with people trying to figure out how to improve and govern their data quality. If you’re at all familiar with my writing, you’ll recognize I have a bias for managing what matters. It’s easy to get distracted by DQ issues as they occur across all facets of the enterprise landscape. So many targets, so little time. Having said that, similar to a governance or master data approach, it’s critical to focus on those quality issues that are most impactful on the business outcomes for the company.
Lastly, log it. Day to day issues should be tracked and captured (a good use case for Agile backlogs) but be careful to avoid their gravitational pull. It’s easy to spend too much time on low impact issues. Keep your eye on the prize, and drive changes to support business epics and goals — this will keep you aligned with leaders, and, as a kind of cool byproduct, it may also keep you well funded.
Don’t Reinvent the Wheel
There are a ton of books, tools and how-tos on managing data quality. That’s beyond the scope of this piece. Having said that, sometimes teams just need a gentle push in the right direction. To that end, it’s important that you choose a process model that you can adapt and adopt to meet your data culture. I really like the approach developed by the Shewhart /Deming cycle, a well known problem-solving model know as ‘plan-do-check-act’.
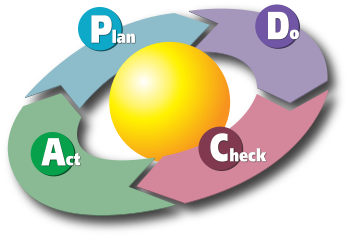
Shewhart/Deming PDCA Model
Originally developed in lean manufacturing, the PDCA cycle easily applies to effective data quality management. It essentially involves the creation of standards that a product is measured against (in this case quality data), followed by root cause analysis of discrepancies, and then remediation.
In the Plan stage, the Data Quality team assesses known issues in order to document, prioritize and lay out a plan and approach to address them. It’s critical that this is based in root cause analysis if you want to understand the impact (cost / benefit).
In the Do stage, the DQ team leads efforts to address the root causes of issues and plan for ongoing monitoring to ensure the standards are being met. For non-technical causes, the team works with process owners on continuous improvement efforts. For technical changes, they engage with technical teams or vendors to ensure requirements get implemented correctly and that technical changes do not introduce new issues.
The Check stage involves active monitoring of data quality, again measured against requirements and standards. This process should implement defined thresholds for quality. If met, no action required. If target data falls below acceptable quality thresholds, however, remediation actions are invoked.
The Act stage is for workflows to understand and correct emerging data quality issues. The cycle restarts as issues are identified and assessed, with new solutions being proposed. A mechanism of continuous improvement, new cycles begin as existing metrics fall below norms or new data sets come into play. Sometimes, data quality requirements emerge for existing data sets based upon changes in business rules, standards, etc.
Final Answer: Trusted Data is Job #1
In the end, it should be clear that managing data quality is an ongoing process. Like any CICD process, clever companies and CDOs establish DQ programs that are stocked with talent and well funded. A healthy program also has all of the right tools to succeed such as a DQ rules/execution engine, a data catalog, etc. To do otherwise is just inviting the R twins (Risk and Rework) to show up.
Fortunately, the remedies to data quality are numerous. As I’ve mentioned however, it takes a commitment to excellence and discipline. While I fear the later is a dying art form in the rush to building technology fortunes, with the right leadership and improvements in Enterprise Stewardship practices, companies can start to put data quality issues and woes in the rear view. This includes those dreadful ‘why is my data bad?’ conversations.
Some readers may know Chris was a contributor/reviewer for DAMA’s Data Management Body of Knowledge V2 book. We raise this here only to acknowledge that as part of that team, he spent considerable cycles on this topic. It should also be noted that on more than one occasion they failed to reach consensus. Still, they persevered and provided what he feels was a well informed perspective on data management. We highly recommend getting a copy of DMBOK v2 if you don’t already have one.